
What is AuroraDB ?
Amazon Aurora is a fully-managed, MySQL-compatible, relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. It delivers up to five times the performance of MySQL without requiring changes to most of your existing applications.
Amazon Aurora makes it simple and cost-effective to set up, operate, and scale your new and existing MySQL deployments, thus freeing you to focus on your business and applications. Amazon RDS provides administration for Amazon Aurora by handling routine database tasks such as provisioning, patching, backup, recovery, failure detection, and repair. Amazon RDS also provides push-button migration tools to convert your existing Amazon RDS for MySQL applications to Amazon Aurora.
Amazon Aurora is a drop-in replacement for MySQL. The code, tools and applications you use today with your existing MySQL databases can be used with Amazon Aurora.
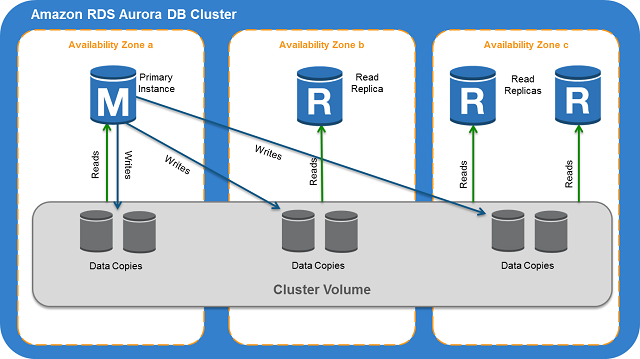
When you create an Amazon Aurora instance, you create a DB cluster. A DB cluster consists of one or more instances, and a cluster volume that manages the data for those instances. An Aurora cluster volume is a virtual database storage volume that spans multiple Availability Zones, with each Availability Zone having a copy of the cluster data. Two types of instances make up an Aurora DB cluster:
- Primary instance – Supports read-write workloads, and performs all of the data modifications to the cluster volume. Each Aurora DB cluster has one primary instance.
- Aurora Replica – Supports only read operations. Each DB cluster can have up to 15 Aurora Replicas in addition to the primary instance, which supports both read and write workloads. Multiple Aurora Replicas distribute the read workload, and by locating Aurora Replicas in separate Availability Zones you can also increase database availability.
The following diagram illustrates the relationship between the Amazon Aurora cluster volume and the primary and Aurora Replicas in the Aurora DB cluster.
Amazon RDS for Aurora Preview
Amazon RDS for Aurora is currently available as a preview release. The preview release provides console access only—no CLI or API access is available. You can access the Amazon Aurora preview release at https://db-preview.aws.amazon.com/rds/home?region=us-east-1.
Your feedback is a valuable part of improving Amazon Aurora. To provide feedback, email us at aurora-PM@amazon.com or go to the Aurora forum, which is a private, regularly monitored forum for Amazon Aurora preview release customers. In the forum we will announce pending changes and induced instability events.
Aurora Endpoints
Each Aurora DB cluster has a cluster endpoint that you can connect to. An endpoint is made up of a domain name and a port separated by a colon, for example: mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com:3306.
The cluster endpoint connects you to the primary instance for the DB cluster. You can perform both read and write operations using the cluster endpoint. The primary instance also has a unique endpoint. The difference between the two endpoints is that the cluster endpoint will always point to the primary instance. If the primary instance fails, then the cluster endpoint will point to the new primary instance. For more information on failovers, see Fault Tolerance for an Aurora DB Cluster.
Each Aurora Replica in an Aurora DB cluster has a unique endpoint. You can configure multiple clients to connect to different Aurora Replicas in an Aurora DB cluster to distribute the read workload for your application. For high-availability scenarios, you can also place Aurora Replicas in separate Availability Zones, which ensures that your application will still be able to read data from your Aurora DB cluster in the event of an Availability Zone failure.
You must connect to the cluster endpoint for high-availability scenarios. This connection ensures that you will continue to have access to the Aurora DB cluster in the event of a failover. During a failover, Aurora continues to serve requests, with minimal interruption of service, to the cluster endpoint from any available instances as it replaces the failed instance.
Consider an Amazon Aurora DB cluster that has two Aurora Replicas in different Availability Zones from its primary instance. By connecting to the cluster endpoint, you can send both read and write traffic to the primary instance. You can also connect to the endpoint for each Aurora Replica and send queries directly to those DB instances. In the unlikely event that the primary instance or the Availability Zone that contains the primary instance fails, then RDS will promote one of the Aurora Replicas to be the new primary instance and update the DNS record for the cluster endpoint to point to the new primary instance. Your application will continue to send read and write traffic to your Aurora DB cluster by using the cluster endpoint with minimal interruption in service.
Amazon Aurora Storage
Aurora data is stored in the cluster volume, which is a single, virtual volume that utilizes solid state disk (SSD) drives. A cluster volume consists of copies of the data across multiple Availability Zones in a single region. Because the data is automatically replicated across Availability Zones, your data is highly durable with less possibility of data loss. This replication also ensures that your database is more available during a failover because the data copies already exist in the other Availability Zones and continue to serve data requests to the instances in your DB cluster.
Aurora cluster volumes automatically grow as the amount of data in your database increases. An Aurora cluster volume can grow to a maximum size of 64 terabytes (TB). However, you can set the maximum size of your database to a value less than 64TB by setting the maximum volume size when you create your Aurora DB cluster, or by modifying the maximum volume size for an existing Aurora DB cluster. By setting the maximum volume size, you can prevent your volume from growing larger than your preferred size. You are only charged for the space that you use in an Aurora cluster volume, so setting a maximum volume size doesn’t increase your storage costs. For pricing information, go to the Amazon RDS product page.
Amazon Aurora Replication
Aurora Replicas are independent endpoints in an Aurora DB cluster. They provide read-only access to the data in the DB cluster volume and enable you to scale the read workload for your data over multiple replicated instances to both improve the performance of data reads as well as increase the availability of the data in your Aurora DB cluster. Aurora Replicas are also failover targets and are quickly promoted if the primary instance for your Aurora DB cluster fails.
For more information on Aurora Replicas and other options for replicating data in an Aurora DB cluster, see Replication with Amazon Aurora.
Amazon Aurora Reliability
Aurora is designed to be reliable, durable, and fault tolerant. You can architect your Aurora DB cluster to improve availability by doing things such as adding Aurora Replicas and placing them in different Availability Zones, and also Aurora includes several automatic features that make it a reliable database solution.
Storage Auto-Repair
Because Aurora maintains multiple copies of your data in three Availability Zones, the chance of losing data as a result of a disk failure is greatly minimized. Aurora automatically detects failures in the disk volumes that make up the cluster volume. When a segment of a disk volume fails, Aurora immediately repairs the segment. When Aurora repairs the disk segment, it uses the data in the other volumes that make up the cluster volume to ensure that the data in the repaired segment is current. As a result, Aurora avoids data loss and reduces the need to perform a point-in-time restore to recover from a disk failure.
“Survivable” Cache Warming
Aurora “warms” the buffer pool cache when a database starts up after it has been shut down or restarted after a failure. That is, Aurora preloads the buffer pool with the pages for known common queries, which provides a performance gain by bypassing the need for the buffer pool to “warm up” from normal database use.
The Aurora page cache is managed in a separate process from the database, which allows the page cache to “survive” independently of the database. In the unlikely event of a database failure, the page cache remains in memory, which ensures that the buffer pool is warmed with the most current state when the database restarts.
Crash Recovery
Aurora is designed to recover from a crash almost instantaneously and continue to serve your application data. Aurora performs crash recovery asynchronously on parallel threads, so that your database is open and available immediately after a crash. For more information, see Fault Tolerance for an Aurora DB Cluster.
Amazon RDS for Aurora Security
Security for Amazon Aurora is managed at three levels:
- To control who can perform Amazon RDS management actions on Aurora DB clusters and DB instances, you use AWS Identity and Access Management (IAM). When you connect to AWS using IAM credentials, your IAM account must have IAM policies that grant the permissions required to perform Amazon RDS management operations. For more information, see Using AWS Identity and Access Management (IAM) to Manage Access to Amazon RDS Resources.
If you are using an IAM account to access the Amazon Aurora console, you must first log on to the AWS Management Console with your IAM account, and then go to the Aurora preview console at https://db-preview.aws.amazon.com/rds/home?region=us-east-1.
- Aurora DB clusters must be created in a Virtual Private Cloud (VPC). To control which devices and Amazon EC2 instances can open connections to the endpoint and port of the DB instance for Aurora DB clusters in a VPC, you use a VPC security group. These endpoint and port connections can be made using Secure Sockets Layer (SSL). In addition, firewall rules at your company can control whether devices running at your company can open connections to a DB instance. For more information on VPCs, see Using Amazon RDS with Amazon Virtual Private Cloud (VPC).
- To authenticate login and permissions for an Amazon Aurora DB instance once a connection has been opened, you take the same approach as with a stand-alone instance of MySQL. Commands such as
CREATE USER,RENAME USER,GRANT,REVOKE, andSET PASSWORDwork just as they do in on-premises databases, as does directly modifying database schema tables. For information, go to MySQL User Account Management in the MySQL documentation.
When you create an Amazon Aurora DB instance, the master user has the following default privileges:
alteralter routinecreatecreate routinecreate temporary tablescreate usercreate viewdeletedropeventexecutegrant optionindexinsertlock tablesprocessreferencesreplication slaveselectshow databasesshow viewtriggerupdate
To provide management services for each DB cluster, the rdsadmin user is created when the DB cluster is created. Attempting to drop, rename, change the password, or change privileges for the rdsadmin account will result in an error.
For management of the DB cluster, the standard kill and kill_query commands have been restricted. Instead, use the Amazon RDS commands rds_kill and rds_kill_query to terminate user sessions or queries on DB instances.
Securing Aurora Data with SSL
Important
Secure Sockets Layer (SSL) connections are currently not supported for the Aurora preview release and will be added at a later time.
Amazon Aurora DB clusters support Secure Sockets Layer (SSL) connections from applications using the same process and public key as Amazon RDS MySQL DB instances.
Amazon RDS creates an SSL certificate and installs the certificate on the DB instance when Amazon RDS provisions the instance. These certificates are signed by a certificate authority. The SSL certificate includes the DB instance endpoint as the Common Name (CN) for the SSL certificate to guard against spoofing attacks. The public key is stored athttps://rds.amazonaws.com/doc/mysql-ssl-ca-cert.pem.
To encrypt connections using the default mysql client, launch the mysql client using the --ssl_ca parameter to reference the public key, for example:
mysql -h mycluster.cluster-c9akciq32.rds-us-east-1.amazonaws.com --ssl_ca=rds-ssl-ca-cert.pem --ssl-verify-server-cert
You can use the GRANT statement to require SSL connections for specific users accounts. For example, you can use the following statement to require SSL connections on the user account encrypted_user:
GRANT USAGE ON *.* TO 'encrypted_user'@'%' REQUIRE SSL
Note
For more information on SSL connections with MySQL, go to the MySQL documentation.
Using the memcached Option with Amazon Aurora
Amazon Aurora DB instances support the MySQL 5.6 memcached option, a simple, key-based cache. For more information about the MySQL memcached option, see MySQL 5.6 memcached Support.
Important
The memcached option is currently not supported for the Aurora preview release and will be added at a later time.
Comparison of Amazon RDS for Aurora and Amazon RDS for MySQL
Although Aurora instances are compatible with MySQL client applications, Aurora has advantages over MySQL as well as limitations to the MySQL features that Aurora supports. This functionality can influence your decision about whether Amazon Aurora or MySQL on Amazon RDS are the best cloud database for your solution. The following table shows the differences between Amazon RDS for Aurora and Amazon RDS for MySQL.
| Feature | Amazon RDS for Aurora | Amazon RDS for MySQL |
|---|---|---|
| Read scaling | Supports up to 15 Aurora Replicas with minimal impact on the performance of write operations. | Supports up to 5 Read Replicas with a noted impact on the performance of write operations. |
| Failover target | Aurora Replicas are automatic failover targets with no data loss. | Read Replicas can be manually promoted to the master DB instance with potential data loss. |
| MySQL version | Supports only MySQL version 5.6. | Supports MySQL versions 5.1, 5.5, and 5.6. |
| AWS region | For the Aurora preview release, Aurora DB clusters can only be created in the US East (N. Virginia) region, us-east-1. | Available in all AWS regions. |
| MySQL storage engine | Supports only InnoDB. Tables from other storage engines are automatically converted to InnoDB.
For information on converting existing MySQL tables to InnoDB and importing into an Aurora cluster, see Migrating Data to an Amazon Aurora DB Cluster. |
Supports both MyISAM and InnoDB. |
| Read Replicas with a different storage engine than the master instance | MySQL (non-RDS) Read Replicas that replicate with an Aurora DB cluster can only use InnoDB. | Read Replicas can use both MyISAM and InnoDB. |
innodb_file_per_table |
Amazon Aurora does not support multiple tablespaces. All tables are in a global tablespace. As a result, MySQL features that rely on innodb_file_per_table, such as compressed or dynamic row format, are not available.
This functionality affects migration of data. For more information, see Migrating Data to an Amazon Aurora DB Cluster. |
You can enable per-table tablespaces and store each InnoDB table and its indexes in a separate file. |