
Unleashing the Power of MongoDB GridFS: A Comprehensive Guide
MongoDB GridFS is a powerful tool that allows developers to store and retrieve large files, such as images, videos, and documents, directly within a MongoDB database. By leveraging GridFS, developers can overcome the limitations of document size restrictions and efficiently manage file storage and retrieval operations. In this comprehensive guide, we will delve into the intricacies of MongoDB GridFS and explore its various features and best practices. Whether you are a seasoned MongoDB user or just getting started, this post will provide you with valuable insights and practical examples to help you harness the full potential of GridFS.
- Understanding GridFS: In this section, we will provide a clear overview of GridFS, explaining its purpose and highlighting the scenarios where it proves to be a suitable solution. We will discuss the key components of GridFS, namely the file collection and the chunks collection, and explain how they work together to store and retrieve files efficiently.
- Working with GridFS: This section will guide you through the process of working with GridFS, from installation and setup to file upload and retrieval. We will demonstrate how to interact with GridFS using the MongoDB drivers and provide code examples in popular programming languages like Python and JavaScript. You will learn how to upload files, query for files based on metadata, and efficiently retrieve files using GridFS.
- Performance Optimization: Efficiency is crucial when dealing with large files, and this section will focus on performance optimization techniques for GridFS. We will discuss strategies such as sharding, indexing, and caching to enhance the performance of file storage and retrieval operations. Additionally, we will explore how to leverage GridFS in a distributed system to handle high-throughput file operations seamlessly.
- Integrating GridFS with Web Applications: GridFS is often used in web applications to store and serve user-generated content. In this section, we will explore how to integrate GridFS with popular web frameworks like Node.js and Django. You will learn how to handle file uploads, serve files efficiently, and leverage GridFS alongside other MongoDB features to build robust and scalable web applications.
- Managing GridFS in Production: Operating GridFS in a production environment requires careful planning and monitoring. We will discuss best practices for backup and disaster recovery, monitoring performance metrics, and scaling GridFS to handle increasing file storage demands. This section will equip you with the knowledge to effectively manage GridFS in a production setup and ensure high availability and reliability.
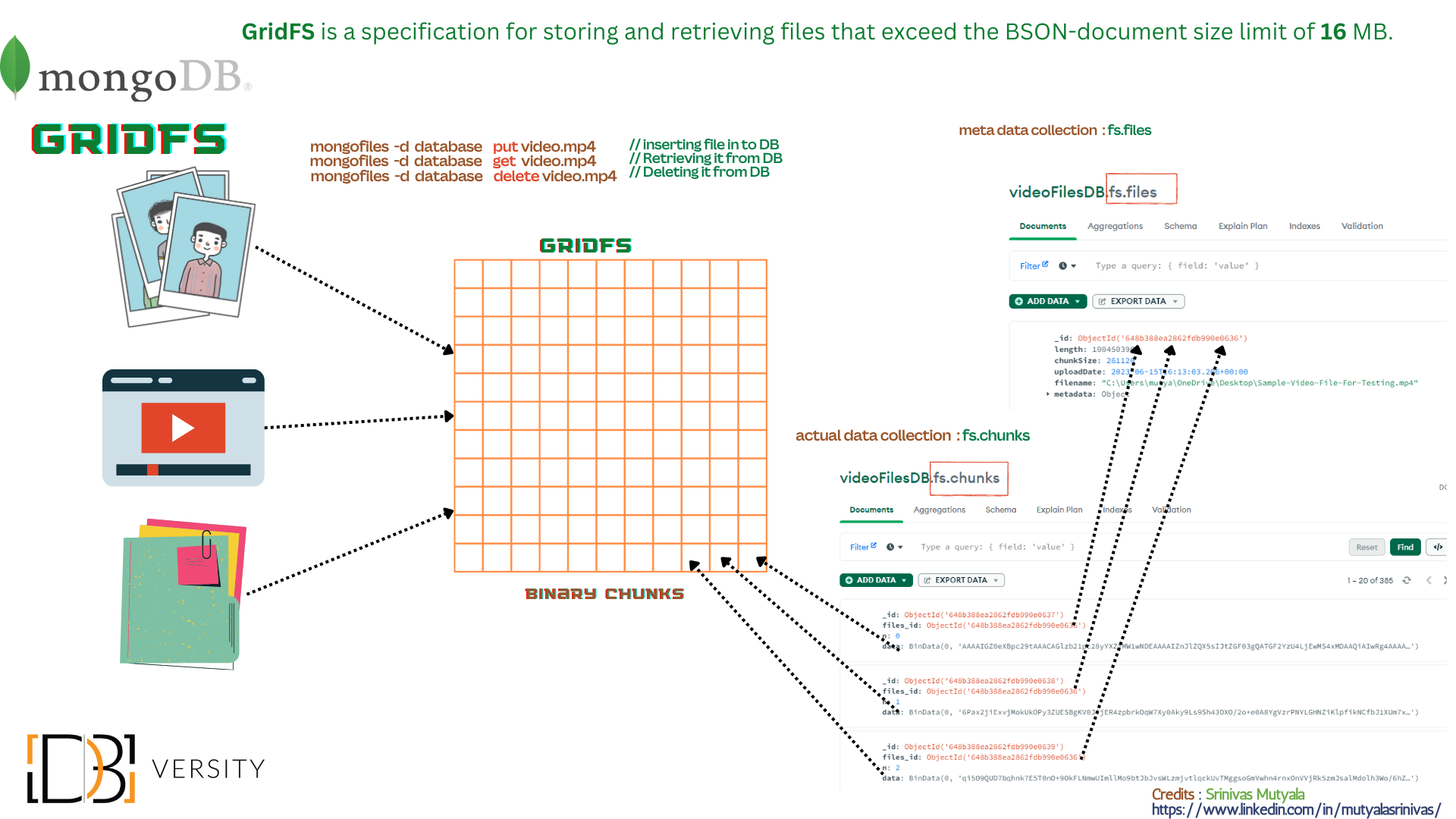
MongoDB GridFS is a file storage system that allows you to store and retrieve large files, such as images, videos, and documents, within a MongoDB database. It is designed to overcome the document size limitations imposed by MongoDB’s BSON document format, which has a maximum size of 16 MB. With GridFS, you can efficiently handle files that exceed this limit by breaking them into smaller chunks and storing them as separate documents.
GridFS achieves this by dividing files into two main collections within the MongoDB database: the file collection and the chunks collection. The file collection stores metadata about each file, such as its filename, content type, size, and any additional custom metadata you want to associate with the file. On the other hand, the chunks collection stores the actual data of the file broken down into smaller chunks.
Here’s a more detailed explanation of the key components and how GridFS works:
- File Collection:
- Each file is represented by a document in the file collection.
- The file document contains metadata fields, such as
_id,filename,contentType,length, anduploadDate. - You can also add custom metadata fields to the file document to store additional information related to the file.
- The file document serves as a reference to the chunks that make up the file.
- Chunks Collection:
- The chunks collection stores the file data broken down into smaller chunks.
- Each chunk is represented by a document in the chunks collection.
- The chunk document contains fields such as
files_id(referring to the_idof the corresponding file document),n(the chunk number), anddata(the actual binary data of the chunk). - By default, each chunk has a maximum size of 255 KB, but the last chunk can be smaller if the file does not evenly divide into chunks.
- Upload Process:
- When you upload a file to GridFS, it gets divided into chunks based on the configured chunk size.
- The chunks are stored in the chunks collection, while the file metadata is stored in the file collection.
- The file document acts as a reference to the corresponding chunks that make up the file.
- This division into smaller chunks allows for efficient storage and retrieval of large files.
- Retrieval Process:
- To retrieve a file from GridFS, you query the file collection using criteria such as the filename or other metadata fields.
- Once you have the file document, you can use the chunks collection to fetch the corresponding chunks.
- The chunks are fetched and reassembled to reconstruct the original file, which can then be accessed and used in your application.
GridFS provides several advantages for storing large files within MongoDB:
- Integration: Files are stored alongside your other MongoDB data, making it easy to manage and query both structured and unstructured data together.
- Scalability: GridFS can handle large files without impacting the performance of other database operations.
- Replication and Fault Tolerance: MongoDB’s replication and sharding features can be applied to GridFS, ensuring data availability and fault tolerance.
Overall, MongoDB GridFS offers a convenient and efficient way to store and retrieve large files within a MongoDB database, providing developers with flexibility and scalability when working with unstructured data.
- Uploading a File to GridFS: To upload a file to GridFS, you can use the
putcommand. Here’s an example:
const { MongoClient } = require('mongodb');
const client = new MongoClient('mongodb://localhost:27017');
async function uploadFileToGridFS(databaseName, collectionName, filePath, fileName) {
try {
await client.connect();
const database = client.db(databaseName);
const bucket = new mongodb.GridFSBucket(database, { bucketName: collectionName });
const uploadStream = bucket.openUploadStream(fileName);
const fileStream = fs.createReadStream(filePath);
fileStream.pipe(uploadStream);
return new Promise((resolve, reject) => {
uploadStream.on('finish', resolve);
uploadStream.on('error', reject);
});
} finally {
await client.close();
}
}
// Usage
uploadFileToGridFS('myDatabase', 'myFiles', 'path/to/file.pdf', 'file.pdf')
.then(() => console.log('File uploaded successfully'))
.catch((error) => console.error('Error uploading file:', error));
- Downloading a File from GridFS: To download a file from GridFS, you can use the
openDownloadStreamcommand. Here’s an example:
async function downloadFileFromGridFS(databaseName, collectionName, fileId, destinationPath) {
try {
await client.connect();
const database = client.db(databaseName);
const bucket = new mongodb.GridFSBucket(database, { bucketName: collectionName });
const downloadStream = bucket.openDownloadStream(fileId);
const writeStream = fs.createWriteStream(destinationPath);
return new Promise((resolve, reject) => {
downloadStream.pipe(writeStream)
.on('finish', resolve)
.on('error', reject);
});
} finally {
await client.close();
}
}
// Usage
downloadFileFromGridFS('myDatabase', 'myFiles', fileId, 'path/to/save/file.pdf')
.then(() => console.log('File downloaded successfully'))
.catch((error) => console.error('Error downloading file:', error));
- Deleting a File from GridFS: To delete a file from GridFS, you can use the
deletecommand. Here’s an example:
async function deleteFileFromGridFS(databaseName, collectionName, fileId) {
try {
await client.connect();
const database = client.db(databaseName);
const bucket = new mongodb.GridFSBucket(database, { bucketName: collectionName });
return new Promise((resolve, reject) => {
bucket.delete(fileId, (error) => {
if (error) {
reject(error);
} else {
resolve();
}
});
});
} finally {
await client.close();
}
}
// Usage
deleteFileFromGridFS('myDatabase', 'myFiles', fileId)
.then(() => console.log('File deleted successfully'))
.catch((error) => console.error('Error deleting file:', error));
These are just a few examples of commands you can use with MongoDB GridFS. You can refer to the official MongoDB documentation (https://docs.mongodb.com/manual/core/gridfs/) for more information and a comprehensive list of GridFS commands and options.
Conclusion: In this comprehensive guide, we have explored the powerful features and capabilities of MongoDB GridFS. We started with an introduction to GridFS and its key components, followed by practical examples of working with GridFS using various programming languages. We then delved into performance optimization techniques, integration with web applications, and best practices for managing GridFS in production. Armed with this knowledge, you are now equipped to leverage GridFS to efficiently store and retrieve large files within your MongoDB applications, unlocking a new level of flexibility and scalability.
Comments are closed, but trackbacks and pingbacks are open.