
MongoDB Sharding Best Practices
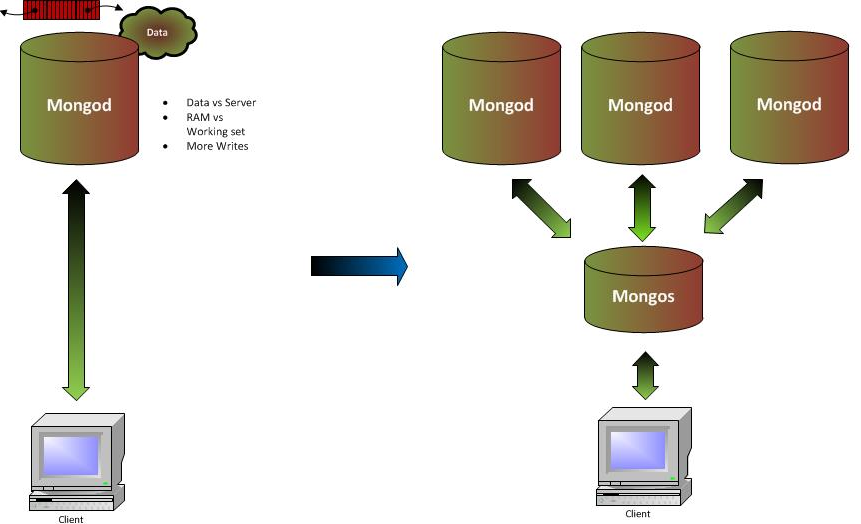
MongoDB Sharding is a complex operation for the db cluster and below are the reasons to shard.
- Whole data doesn’t fit on one server’s storage (Disk Space)
- Disk IO & CPU
- Working set doesn’t fit in one server’s RAM
- Write volume is too high for one server’s disk
- Client network latency on writes (Tag aware sharding)
- Ability to control data location e.g., where data is not allowed outside of NAM
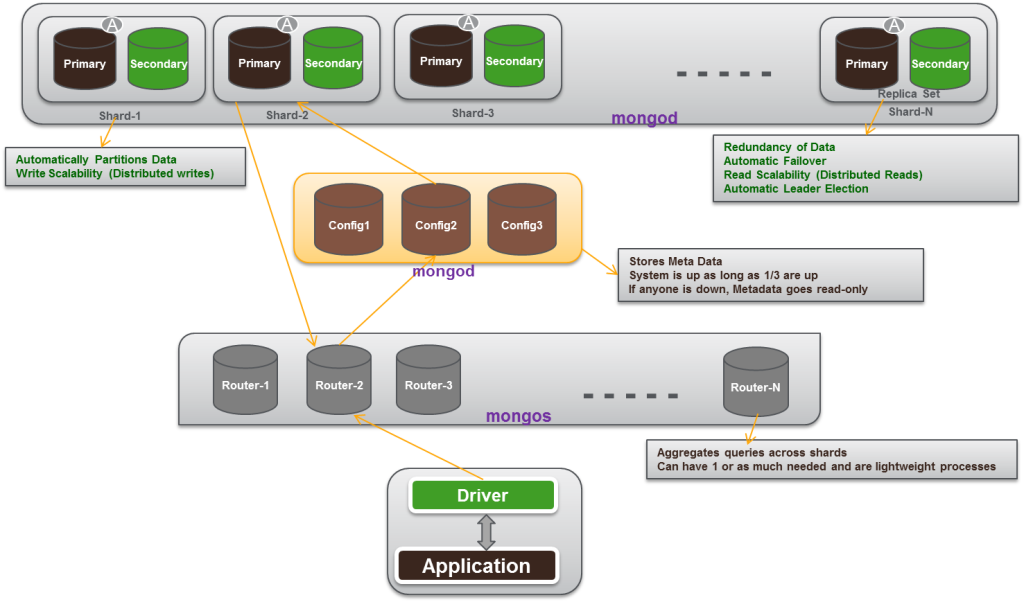
Picking a Shard Key
Shard key is immutable
Shard key values are immutable
Shard key must be indexed
Shard key limited to 512 bytes in size
Shard key used to route queries
– Choose a field commonly used in queries
Only shard key can be unique across shards
-`_id` field is only unique within individual shard
–Create a Shard Key that is Easily Divisible
-An easily divisible shard key makes it easy for MongoDB to distribute content among the shards. Shard keys that have a limited number of possible values can result in chunks that are “unsplittable”. For instance, if a chunk represents a single shard key value, then MongoDB cannot split the chunk even when the chunk exceeds the size at which splits occur.
–
–Create a Shard Key that has High Degree of Randomness
-A shard key with high degree of randomness prevents any single shard from becoming a bottleneck and will distribute write operations among the cluster.
–
–Create a Shard Key that Targets a Single Shard
-A shard key that targets a single shard makes it possible for the mongos program to return most query operations directly from a single specific mongod instance. Your shard key should be the primary field used by your queries. Fields with a high degree of “randomness” make it difficult to target operations to specific shards.
–
–Shard Using a Compound Shard Key
-The challenge when selecting a shard key is that there is not always an obvious choice. Often, an existing field in your collection may not be the optimal key. In those situations, computing a special purpose shard key into an additional field or using a compound shard key may help produce one that is more ideal.
- Cardinality: how much data for a single value?
- Write distribution: how many shards are written to?
- Query isolation: how many shards will be hit?
- Reliability: how much of the system is affected by a shard failure?
- Index locality: how much of the key’s index needs to be in RAM?
- Shard key should be in every query if possible – Scatter & gather Otherwise
- Choosing a good shard key is important !
ü – Affects performance & scalability
ü – Changing it later is expensive
The perfect Shard key is when ….
- All inserts, updates, and deletes would each be distributed uniformly across all of the shards in the cluster
- All queries would be uniformly distributed across all of the shards in the cluster
- All operations would only target the shards of interest: an update or delete would never be sent to a shard which didn’t own the data being modified
1)Compute a more ideal shard key in your application layer, and store this in all of your documents, potentially in the _id field.
2)Use a compound shard key that uses two or three values from all documents that provide the right mix of cardinality with scalable write operations and query isolation. ( Ex., _id, pincode, ts..etc)
3)Determine that the impact of using a less than ideal shard key is insignificant in your use case, given:
olimited write volume,
oexpected data size, or
oapplication query patterns.
o
4)Use a hashed shard key. Choose a field that has high cardinality and create a hashed index on that field. MongoDB uses these hashed index values as shard key values, which ensures an even distribution of documents across the shards
5) Check the “cardinality/no. of shards” ratio while selecting the shard key.
Few use cases/considerations
Auto increment field as a Shard key :-
If you defined _id/ user_id (or any field) as a auto increment at your Application and defined your ranges as below
Shard1 : -infinity –> 0 i.e., [-inf,0]
Shard2 : 0 –> 99,999 i.e., [0,99,999]
Shard3 : 99,999 –> infinity i.e., [99,999,inf]
As time goes by (i.e.., your field reaches to values of 99,999) all the writes goes to only Shard-3, so idea of using Auto increment as a Shard key is not that good idea.
- Shard key can not exceed 128 characters, if you try so Mongo doesn’t create an Index for that Shard key and as a result such sharded collection without index for sharding key will case performance degradation.
Please avoid floating-point values as shard keys.- After sharding a collection with a hashed shard key, you must use the MongoDB 2.4 or higher mongosand mongodinstances in your sharded cluster.
- Do not drop the index on the Shard key in prod, for now MongDB will allow you to do so even if the collection is non-empty. This will have big performance implications especially on Migrations.
- Sharding Operational Restrictions are at https://docs.mongodb.org/manual/reference/limits/#sharded-clusters
Sharding – Do’s & Don’ts
Do’s
- Run 3 mongos on 1st Shard nodes.
- Better we locate them on different nodes.
- Use 3 node replica sets for each shard
Don’ts
- Run many mongos behind a load balancer
- Run only 1 Configdb, or 3 on the same server
Balancing Tips
- Run the balancer at low traffic times
mongos> db.settings.update({_id: “balancer”}, {$set : { activeWindow: { start: “9:00”, stop: “21:00”}}})
mongos>
mongos>
mongos> db.settings.find()
{ “_id” : “chunksize”, “value” : 64 }
{ “_id” : “balancer”, “activeWindow” : { “start” : “9:00”, “stop” : “21:00” }, “stopped” : false }
mongos>
- Can be triggered manually using moveChunk.
Tag Aware Sharding :
MongoDB supports tagging a range of shard key values to associate that range with a shard or group of shards.
Those shards receive all inserts within the tagged range. The balancer obeys tagged range associations, which enables the following deployment patterns:
Isolate a specific subset of data on a specific set of shards.
Ensure that the most relevant data reside on shards that are geographically closest to the application servers.
Considerations
- Shard key range tags are distinct from replica set member tags.
- Hash-based sharding does not support tag-aware sharding.
- Shard ranges are always inclusive of the lower value and exclusive of the upper boundary.
Behavior and Operations
The balancer migrates chunks of documents in a sharded collections to the shards associated with a tag that has a shard key range with an upper bound greater than the chunk’s lower bound.
During balancing rounds, if the balancer detects that any chunks violate configured tags, the balancer migrates chunks in tagged ranges to shards associated with those tags.
After configuring tags with a shard key range, and associating it with a shard or shards, the cluster may take some time to balance the data among the shards. This depends on the division of chunks and the current distribution of data in the cluster.
MongoDB Fragmentation issue :
When we’ve huge number of write operations in the system, especially updates & deletes – there’ll be more possible fragmented data in the database due to aggressive internal move chunks.
We can estimate whether the node has Fragmentation in it and we can set-up alerting using the below MongoDB Fragmentation Estimator script.
It will suggest Possible Fragmentation & review schema issues.
Please refer my post on how this script works.
Sharding- Query fail errors – getting partial data
We’ll observe queries give errors when any complete shard (all nodes in that replica set) goes down. We’ll see errors in all queries which has to fetch data from the shard which is down. And even if our query has to fetch some data from both other available shards & the shard which is down – we’ll see errors, not even partial data.
Solution to get the partial data in the above scenario is to use Partial query addOption mentioned below.
Changing the shard key after sharding a collection possible ?
Not at all possible !
There is no automatic support in MongoDB for changing a shard key after sharding a collection. This reality underscores the importance of choosing a good shard key before starting your production.
If you must change a shard key after sharding a collection, the best option is to:
üDump all data from MongoDB into an external format.
üDrop the original sharded collection.
üConfigure sharding using a more ideal shard key.
üPre-split the shard key range to ensure initial even distribution.
üRestore the dumped data into MongoDB.
Backup and Restore Sharded Clusters
MongoDB Backup Methods are ….
qBackup by Copying Underlying Data Files
qBackup with mongodump
qOps Manager Backup Software
1) Backup a Small Sharded Cluster with mongodump
If your sharded cluster holds a small data set, you can connect to a mongos using mongodump.
You can create backups of your MongoDB cluster, if your backup infrastructure can capture the entire backup in a reasonable amount of time and if you have a storage system that can hold the complete MongoDB data set.
mongodump –host hostname.example.net –port 37017 –username user –password pass –out /opt/backup/mongodump-2015-10-24
To restore
mongorestore –host hostname.example.net –port 37017 –username user –password pass –collection <collection_name> –db <db_name> dump/database.bson
2) Backup a Sharded Cluster with Filesystem Snapshots
This procedure applies to the MMAPv1 storage engine only and describes a procedure for taking a backup of all components of a sharded cluster.
This procedure uses file system snapshots to capture a copy of the mongod instance.
If the volume where MongoDB stores data files supports point in time snapshots, you can use these snapshots to create backups of a MongoDB system at an exact moment in time.
File systems snapshots are an operating system volume manager feature, and are not specific to MongoDB. The mechanics of snapshots depend on the underlying storage system. For example, if you use Amazon’s EBS storage system for EC2 supports snapshots. On Linux the LVM manager can create a snapshot.
Journling should be enabled.
Balancer should be disabled.
If your storage system does not support snapshots, you can copy the files directly using cp, rsync, or a similar tool. Since copying multiple files is not an atomic operation, you must stop all writes to the mongod before copying the files. Otherwise, you will copy the files in an invalid state.
4) Ops Manager Backup Software
MongoDB Subscribers can install and run the same core software that powers MongoDB Cloud Manager Backup on their own infrastructure.
Ops Manager, an on-premise solution, has similar functionality to the cloud version and is available with Enterprise Advanced subscriptions.
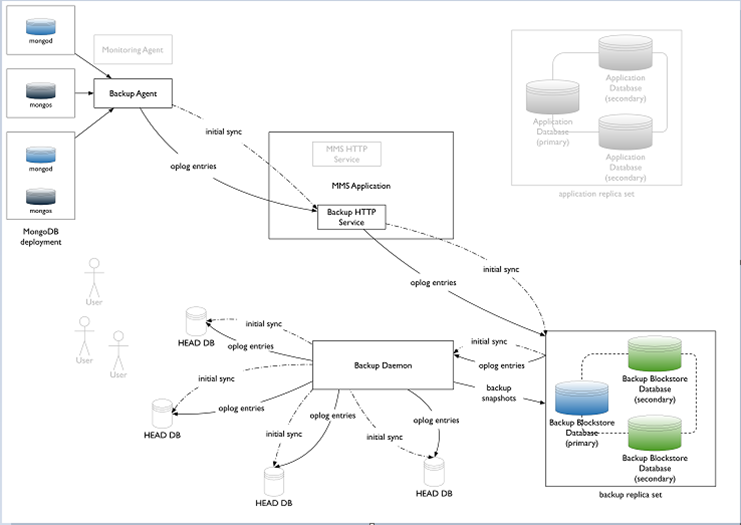
BACKUP & RESTORE PROCESS FLOW
- After installing packages for MMS Backup and agent, we need to start Backups for the desired Replica set and Authentication mechanism.
- Upon clicking the REPLICA SET – you’ll get information on snapshots, oplog slices getting copied and also sync status.
- Backup tap also has options to change snapshot schedule and also to choose specific namespace for backup and also to change credentials.
- Snapshot schedule tool supports taking daily, weekly and monthly with specific time intervals and it also support PIT restores.
- With every replica set backup created, corresponding snapshots can be restored and deleted too.
- In order to restore data, SCP & HTTPS are the supported mechanisms. For SCP, we can choose individual DB files or the entire data in a compressed format.
- HTTPS method involves generating a download link which is valid for 1hour.
- For SCP of the data, a key value pair must be generated and copied to the users home directory of corresponding machine to which data must be copied.
- Additional features available in the UI under Admin tab include options to check info on blockstores, Sync store, Oplog stores, logs, Jobs etc.
qMongoDB Cloud Manager Backup
MMS/Ops Manager Backup – Restore
Evaluation of Ops Manager backup & restore at :
Upgrade process for Sharded Cluster
1) Disabling the Balancer connecting to mongos by issuing following command
To stop : sh.stopBalancer() OR db.settings.update( { _id: “balancer” }, { $set : { stopped: true } } , { upsert: true } )
To verify : sh.getBalancerState()
To verify whether there’re any migrations are in progress after disabling, connect to config db from mongo shell and issue below command.
while( sh.isBalancerRunning() ) { print(“waiting…”); sleep(1000);}
2) Upgrading the cluster’s meta data with –upgrade options as below. First try with single mongos instead of doing it on all mongos
mongos –configdb <configDB string> –logpath /<logs_location>/mongos.log –upgrade
The mongos will exit upon completion of the –upgrade process.
3) Ensure mongos –upgrade process completes successfully by observing the following messages from the log file.
<timestamp> I SHARDING [mongosMain] upgrade of config server to v6 successful
…
<timestamp> I – [mongosMain] Config database is at version v6
After a successful upgrade, restart the mongos instance. If mongos fails to start, check the log for more information.
If the mongos instance loses its connection to the config servers during the upgrade or if the upgrade is otherwise unsuccessful, you may always safely retry the upgrade.
4) Upgrading the remaining mongos instances to required version.
Upgrade and restart without the –upgrade option the other mongos instances in the sharded cluster.
Please do remember do not upgrade the mongod instances until after you have upgraded all the mongos instances.
5) Upgrading the config servers
After you have successfully upgraded all mongos instances, upgrade all 3 mongod config server instances, leaving the first config server listed in the mongos –configdb argument to upgrade last.
6) Upgrading the shards
Upgrade each shard, one at a time, upgrading the mongod secondaries before running replSetStepDown and upgrading the primary of each shard.
7) Re-enable the balancer.
Once the upgrade of sharded cluster components is complete, Re-enable the balancer.
To enable the balancer, connect to monogs issue any of below commnad.
sh.setBalancerState(true) OR
db.settings.update( { _id: “balancer” }, { $set : { stopped: false } } , { upsert: true } )
Recommendations :
Always good to have a backup of config dbs before upgrading.
Do not run either sh.shardDatabase() or sh.shardCollection() (or the command equivalents) while the upgrade is taking place.
Sharded Cluster – trouble shooting tips
The Major issues that we may encounter with Sharded Cluster are below.
Config Database String Error
Start all mongos instances in a sharded cluster with an identical configDB string. If a mongos instance tries to connect to the sharded cluster with a configDB string that does not exactly match the string used by the other mongos instances, including the order of the hosts, the following errors occur:
could not initialize sharding on connection
And: mongos specified a different config database string
To solve the issue, restart the mongos with the correct string.
Cursor Fails Because of Stale Config Data
A query returns the following warning when one or more of the mongos instances has not yet updated its cache of the cluster’s metadata from the config database:
could not initialize cursor across all shards because : stale config detected
This warning should not propagate back to your application. The warning will repeat until all the mongos instances refresh their caches. To force an instance to refresh its cache, run the flushRouterConfig command.
Avoid Downtime when Moving Config Servers
Use CNAMEs to identify your config servers to the cluster so that you can rename and renumber your config servers without downtime.
Additional Resources
Sharding Methods for MongoDB (Presentation)
Everything You Need to Know About Sharding (Presentation)
MongoDB for Time Series Data: Sharding
MongoDB Operations Best Practices White Paper
Talk to a MongoDB Expert About Scaling