
MongoDB Sharding Techniques
MongoDB Sharding Techniques
Sharding is the horizontal partitioning technique used in MongoDB to distribute data across multiple servers. This improves scalability, performance, and high availability. Below are the key sharding techniques used in MongoDB:
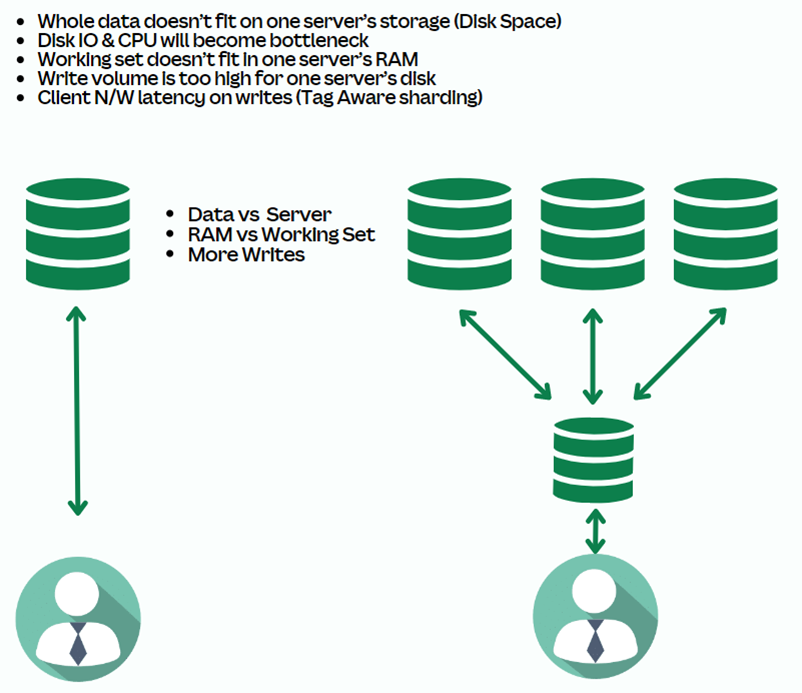
Why Sharding ?
MongoDB Sharding is a complex operation for the db cluster and below are the reasons to shard.
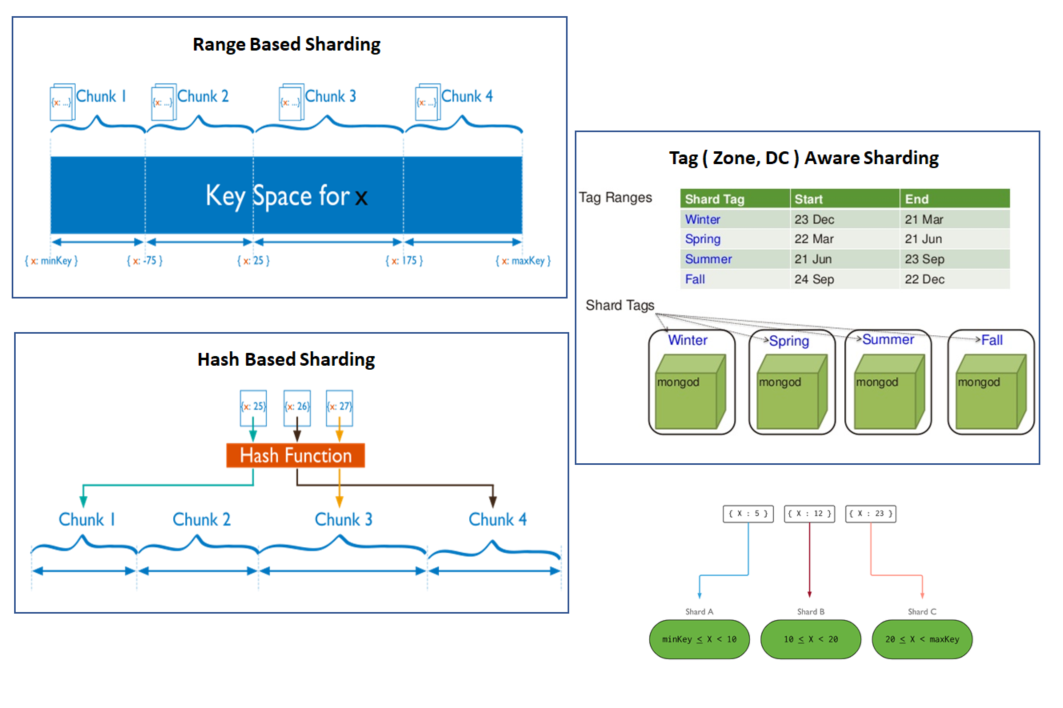
- Hashed Sharding
Concept:
- MongoDB hashes the shard key value using a consistent hashing algorithm and distributes the data across shards.
- Ensures even data distribution but does not guarantee range-based query efficiency.
Use Case:
✔ When workload involves random reads/writes (e.g., user sessions, logs).
✔ Avoids hotspots by distributing data evenly.
✖ Not ideal for range-based queries as data is not sequentially stored.
Example:
sh.shardCollection(“mydb.mycollection”, { “userId”: “hashed” })
This will hash the userId field before storing the documents in shards.
- Range-Based Sharding
Concept:
- Documents are stored in shards based on a specific range of shard key values.
- Each shard is responsible for a continuous range of values.
Use Case:
✔ Efficient for range queries (e.g., retrieving users by date range).
✔ Best suited when query patterns involve sorting or aggregation over a range.
✖ If the shard key is monotonically increasing (e.g., timestamps), one shard may get overloaded (hotspot issue).
Example:
sh.shardCollection(“mydb.sales”, { “orderDate”: 1 })
Data is partitioned based on orderDate, where each shard holds a different date range.
- Zone-Based (Tag-Aware) Sharding
Concept:
- Extends range-based sharding by assigning zones to specific shards.
- Useful when geographically distributing data or keeping certain data in specific regions.
Use Case:
✔ Regulatory compliance (e.g., EU customer data must stay in Europe).
✔ Data locality for latency optimization.
✔ Reducing inter-region network costs.
Example:
sh.addShardToZone(“shard0001”, “EU”)
sh.addShardToZone(“shard0002”, “US”)
sh.updateZoneKeyRange(“mydb.customers”, { “region”: “EU” }, { “region”: “EU” }, “EU”)
This ensures EU customers are stored in shard0001 and US customers in shard0002.
Choosing the Right Sharding Key
Selecting the right shard key is critical for performance:
| Sharding Type | Query Efficiency | Load Balancing | Range Queries |
| Hashed Sharding | ❌ Slow | ✅ Evenly distributed | ❌ Inefficient |
| Range-Based Sharding | ✅ Efficient | ❌ Risk of hotspots | ✅ Efficient |
| Zone-Based Sharding | ✅ Efficient | ✅ Controlled | ✅ Efficient |
Best Practices for Choosing a Shard Key:
✔ High cardinality: Large number of unique values for even data distribution.
✔ Even distribution: Avoid selecting a monotonically increasing key (like timestamps).
✔ Query pattern optimization: Match the shard key with frequent query filters.
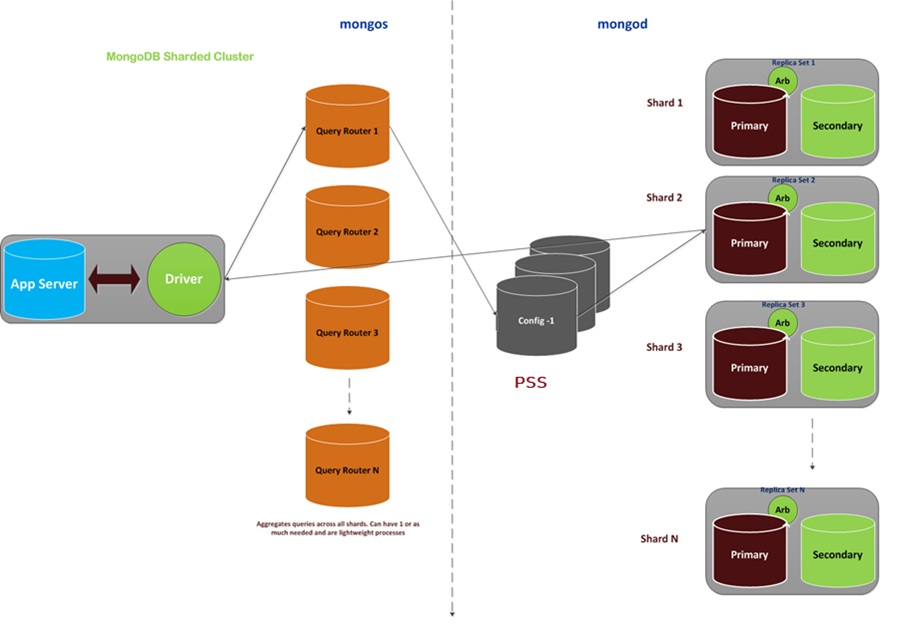
Sharding Architecture
MongoDB’s sharded cluster consists of:
- Config Servers (CSRS): Stores metadata and manages shards.
- Shards: Holds the actual data.
- Mongos Router: Routes queries to the appropriate shard.
Example Sharded Cluster Setup
# Step 1: Add shards
sh.addShard(“shard1.example.com:27017”)
sh.addShard(“shard2.example.com:27017”)
# Step 2: Enable sharding for the database
sh.enableSharding(“mydb”)
# Step 3: Shard a collection
sh.shardCollection(“mydb.mycollection”, { “customerId”: “hashed” })
Conclusion
MongoDB sharding techniques help in scalability and performance optimization. The choice depends on your workload:
- Hashed Sharding → Randomly distributed writes (avoid hotspots).
- Range-Based Sharding → Querying data sequentially by a field.
- Zone-Based Sharding → Compliance or locality-based partitioning.
Comments are closed, but trackbacks and pingbacks are open.