
Implementing The Classic Order Entry Schema In Couchbase
I have been thinking for a while now about how to implement a classic Order Entry schema in a document database. I have been considering this not as some enterprise implementation of commercial product, more as a thought exercise. Trying to do this presents several problems which I will outline below. In a flexible schema database like Couchbase we do not have the concept of joins and foreign keys. As a result of this we are normally tempted to put everything (order, order details etc) into one large document along with the customers core details. This has a few advantages like performance and having all the customers details and orders in one location, but it does not serve the purposes I want which is to have more flexibility in querying the data.
The first thing I did was to look for a schema that already existed rather than reinvent my own. Many relational OE schemas exist and I found the one below from MySQL as good as any so went with that. I am not going to implement the whole schema, just Customers, Orders, OrderDetails and Products.
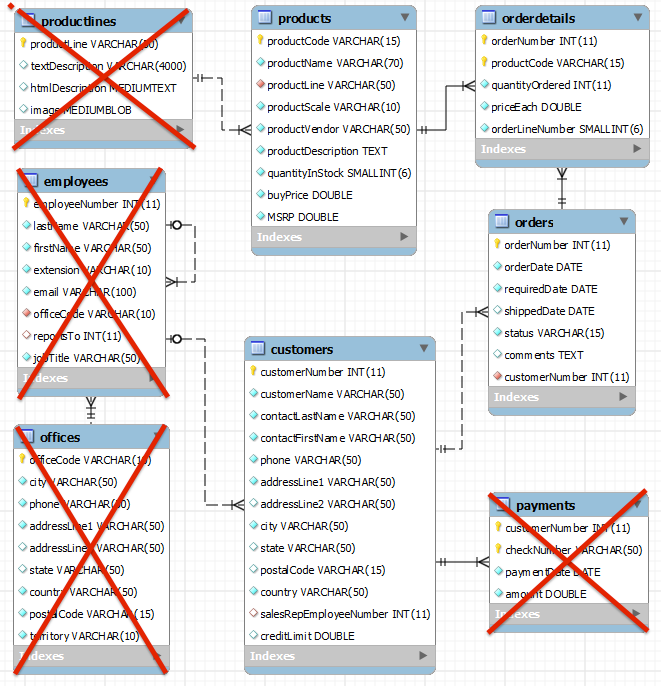
So the first thing I did was create a data data bucket on my Couchbase database called order-entry. I made this bucket about 200MB in size as I only plan on loading a small amount of data. The size of the bucket does not really matter, we are trying to make an optimal schema here, nothing more.
If we think about dependencies that we need to implement it boils down to be quite simple really. Reading down on the left side of the info graphic below and reading back up the right side.
CUSTOMERS
Can Have Must Have
ORDERS
Can Have Must Have
ORDERLINES
Must Have Can Have
PRODUCTS
So these are the constraints we are imposing on the system.
CUSTOMER Can Have ORDERS – (Not all customer may place an order)
ORDERS Can Have ORDERLINES – (An order may or may not have order items)
ORDERLINES Must Have PRODUCTS – (You cannot order nothing)
ORDERLINES Must Have ORDERS – (You cannot have orphan order lines)
ORDERS Must Have CUSTOMERS – (Each order must be associated with a Customer)
Customer – (Remember we also have the ID as a field we create for each document)
{“customerName” : “Couchbase Inc”,
“contactLastName” : “Murphy”,
“contactFirstName” : “Diane”,
“phone” : “555-4856”,
“addressLine1” : “The Penthouse”,
“addressLine2” : “2000 El Camino Real”,
“city” : “Mountain View”,
“state” : “NY”,
“postalCode” : “90210”,
“country” : “USA”,
“salesRepEmpNum” : 988354329,
“creditLimit” : 320000,
“docStatus” : “Active”,
“docType” : “Customer”}
Product
{“productName” : “The Test Product”,
“productDescription” : “This is a test product”,
“productStatus” : “In Stock”,
“quantityInStock” : 100,
“buyPrice” : 25.95,
“sellPrice” : 45.00,
“docStatus” : “Active”,
“docType” : “Product”}
Order
{“customerID” : “1234567890C123456”,
“orderDate” : “29-Sep-2014”,
“requiredDate” : “14-Oct-2014”,
“shippedDate” : “31-Dec-3000”,
“status” : “Pending”,
“comments” : “Customer needs goods a quickly as possible”,
“docStatus” : “Active”,
“docType” : “Order”}
OrderLine
{“orderID” : “1234567890C123456”,
“productID” : “9836458384P292714”,
“quantity” : “14”,
“price” : “31.95”,
“orderLineNum” : “1”,
“docStatus” : “Active”,
“docType” : “OrderLine”}
Remember, all of these document reside in the same bucket and are defined by their docType field and the letter contained in their Document ID (C,P,O,OL). (I know this is a little redundancy, but I included more for completeness.)
But lets think about what we have here when we look at Orders specifically. To a business Orders are an single thing really. A customer does not place and order, then place the order lines separately. We only do this as a convention to accommodate the limitation a relational world imposes upon us. So we can redesign the ORDER and ORDERLINE documents into one document with ORDERLINES as an array of embedded documents
Order
{“customerID” : “1234567890C123456”,
“orderDate” : “29-Sep-2014”,
“requiredDate” : “14-Oct-2014”,
“shippedDate” : “31-Dec-3000”,
“status” : “Pending”,
“orderLines” : [
{“prdID” : “9836458384P292714”, “qty” : “14”, “price” : “31.95”,“LineNum” :”1″},
{“prdID” : “9816458886P262514”, “qty” : “14”, “price” : “56.05”,“LineNum” :”2″}],
“comments” : “Customer needs goods a quickly as possible”,
“docStatus” : “Active”,
“docType” : “Order”}
This is more in line with how we think or customer orders, and it reduces the number of documents (entities) we need to manage.
Ok, now we have out data model sorted out lets look at the code modules we will need.
- Generate unique ID
- Insert CUSTOMER
- Update CUSTOMER
- Insert PRODUCT
- Update PRODUCT
- Create ORDER
- Update ORDER
- Find Customer
Note: We have limited functionality and also we do not delete CUSTOMERs, PRODUCTs, ORDERs or ORDERLINEs. We will mark them as “Deleted”.
After a bit of thinking I realised that I did not need all the Insert functions and I could get by with one generic one that I passed the document into. So the new code modules would be:
- Generate unique ID
- Insert document
- Update CUSTOMER
- Update PRODUCT
- Update ORDER
- Find Customer
In the interests of time (and a hectic schedule) I will not be doing any validation or error checking in this blog post, so apologies. You can assume that the code presented here is for demonstration purposes only and would need a lot more work to make it industrial.
As you may or may not know one of the strengths of Couchbase is that every document must have a unique ID. It is this ID that is used when distributing the documents across the cluster. Letting Couchbase do this for you means that we get an even distribution of records across the cluster. Other document database allow you to pick the shard key, this can result in poor performance and a very uneven distribution of documents across the cluster. As all our documents are going to be in the one bucket we cannot risk having duplicate IDs as this will cause an error. There are a few ways of doing this, and in my opinion one is as good as the other.
For instance we could use a sequence generator and assign every document a unique value. There is a danger that we could assign the same key to 2 documents, and there is the difficulty of managing the sequence.
Again we could use some kind of sequence generator assigning an ID to each document and prefix document type initials (C for CUSTOMER, O for ORDER etc) to each document. This would lessen the chances of duplicate keys by a factor but still leaves the headache of key management.
The option I will choose is to use an epoch timestamp down to micro-second and append the initial of the document type followed by a random number. This will give me (hopefully) uniqueness and allow the key to be used as a timestamp and a document type identifier. So for a duplicate ID to be generated it would require two documents to be inserted at the exact same time, for them to be of the same type and for the random number generator to return the same number. Possible, but unlikely.
A document id will be of the format 9999999999999C999999 for a customer document.
The code for generate the Document Identifiers is very simple and takes one parameter returning a docID. The parameter is the type of document we are inserting and is analogous to the Table Name in the relational model.
Values are:
P = Product
C = Customer
O = Order
function makeID(docType){
//if docType not in (P, C, O) raise and error
return Date.now() + docType + Math.floor(Math.random() * 1000000);
//error handling goes here
}
calling the function
id = makeID(“C”);
Returns
1412022012189C479683
Now lets look at the code for insertDocument
function insertDoc(docID, docData){
var http = require(“http”);
// load the Couchbase driver and connect to the cluster
var couchbase = require(‘couchbase’);
var cluster = new couchbase.Cluster();
var bucket = cluster.openBucket(‘order-entry’);
if(err) {
console.error(“Failed to connect to cluster: ” + err);
process.exit(1);
}
console.log(‘Couchbase Connected’);
});
//create the record
bucket.insert(docID, docData, function(err, result) {
if (err) {
// Failed to retrieve key
throw err;
}
process.exit(0);
})
};
To insert a CUSTOMER we setup a call similar to this
var new_customer =
{“customerName” : “Couchbase Inc”,
“contactLastName” : “Murphy”,
“contactFirstName” : “Diane”,
“phone” : “555-4856”,
“addressLine1” : “The Penthouse”,
“addressLine2” : “2000 El Camino Real”,
“city” : “Mountain View”,
“state” : “NY”,
“postalCode” : “90210”,
“country” : “USA”,
“salesRepEmpNum” : 988354329,
“creditLimit” : 320000,
“docStatus” : “Active”,
“docType” : “Customer”};
// perform some data validation here
// like creditLimit cannot be < 0,
// address validation etc;
//insert the document making an inline call to create the ID
var x = setDoc(makeID(“C”), new_customer);
The process is the same for PRODUCT and ORDER. It is very simple really.
We will write a generic update too similar to what we did with document insertion. Saying update is actually incorrect as Couchbase takes the whole document and rewrites it. For this I will use the upset method. I could have been lazy and used the upsert method for the creation of documents too but I wanted to have checking in place to ensure that the ID did not already exist on the database. Upsert will overwrite existing documents and I did not want this to happen for document creation. As a result of this the new code modules that we are required to write have diminished to:
- Generate unique ID
- Insert document
- Update document
- Find Customer
function updateDoc(docID, docData){
var http = require(“http”);
// load the Couchbase driver and connect to the cluster
var couchbase = require(‘couchbase’);
var cluster = new couchbase.Cluster();
var bucket = cluster.openBucket(‘order-entry’);
if(err) {
console.error(“Failed to connect to cluster: ” + err);
process.exit(1);
}
console.log(‘Couchbase Connected’);
});
bucket.upsert(docID, docData, function(err, result) {
if (err) {
// Failed to retrieve key
throw err;
}
process.exit(0);
})
};
Again we can use this code for all Updates and “Deletes”. To Delete we just set the docStatus field to “Deleted”.
We now have created three of our four code modules. The last code module (Find Customer) will require us to create a view in Couchbase to allow us to lookup the CUSTOMER Document ID by Customer Name. Creating a view is very simple in Couchbase and gives us the power to put an index on the Customer Name that returns the Customer ID. We then can use this ID as the Key to retrieving the Customer Document(s).
Firstly we open the Couchbase console and navigate to the Views section. Select the order-entry bucket and click on Create Development View. Fill in the details, naming your view customer_lookup and press save.
Next press the Edit button so we can customise our view. We want to change the view code from the default to use CusomerName but only on documents where the DocType = ‘Customer’. Amend the Map section with the code below and press Save.

Next press Show Results to check that your view returns the data you want.
Finally return to the Views overview screen by clicking on the Views link and press the Publish button to make the view production.
We now have the ability to find the CustomerID by using the CustomerName. So lets write the code to do just that. This code will take a Customer Name and return an ID. This ID can then be used to fine the Oder Details for that Customer. This is very basic, but it is easy to expand this further as required.
function findCustomer(customerName){
var cluster = new couchbase.Cluster();
var bucket = cluster.openBucket(‘order-entry’, function(err){
if (err) throw err;
for (var i = 0; i < results.length; ++i) {
keys.push(results[i].key);
}
console.log(keys);
What we have now is a basic outline on how to transform a relational schema into a document based schema and a very basic way of interacting with it. I hope you found this helpful and please post any additions or finding in the comments below.
Thanks Owen for the post & detailed explanation.